图 3、4为污水处理厂2019年真实污水数据的曲线图,共采集、分析9种污水数据,包括好氧前端DO、好氧末端TSS、进水TP、出水pH、温度T、进水SS、进水COD、进水氨氮和缺氧前端ORP. 通过分析,污水数据DO质量浓度存在较大的数据噪声和缺失.

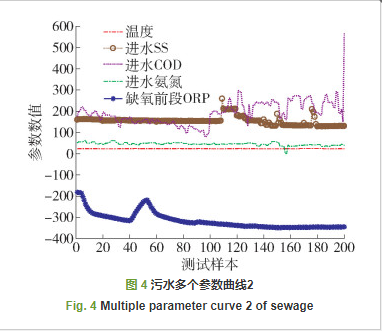
图 5、6分别为基于密度聚类算法和基于K-means聚类算法的城市污水数据异常情况分析图. 从图 5可以看出,pH数据集中分布在7.98~8.07,符合数据正常区间;DO质量浓度数据分布在0~1.6 mg/L,数据波动较大,存在离群点和噪声点数据,并且部分数据缺失或采样点为“0”值,采用密度聚类算法可以精确地识别噪声点和离群点. 从图 6中可以看出,采集数据的分布情况、存在缺失值和“0”值的异常点,但识别噪声点和小聚类簇结果较差.
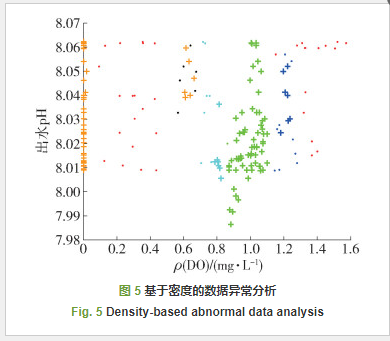
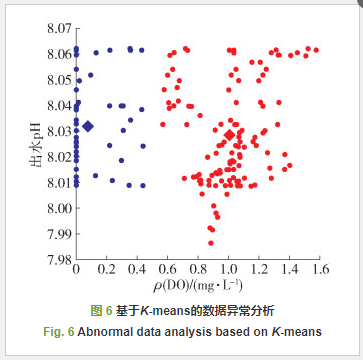
图 7为城市污水数据的相关性分析结果,图像颜色为0~1的相关性大小. 从图中可以看出,部分城市污水变量具有较大相关性,如好氧末端TSS与温度T、进水TP、进水COD,好氧前端DO与进水SS、缺氧前端ORP、进水COD具有较大相关性. 基于ISVM的污水数据清洗方法对于城市污水处理过程中采样数据存在噪声和数据缺失的情况能够根据城市污水数据相关性的特点进行噪声数据的剔除和缺失数据补偿.
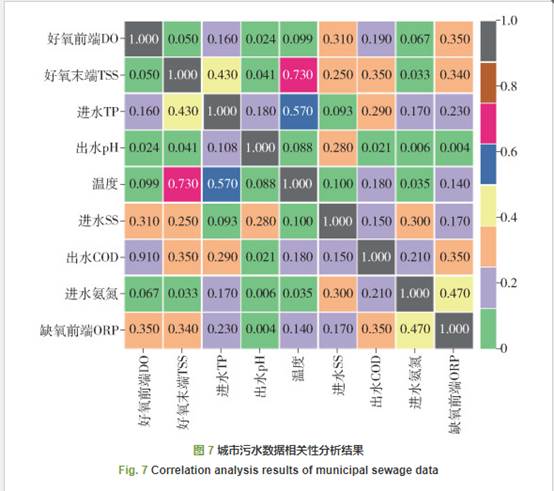
图 8、9分别给出基于ISVM的污水数据清洗方法和基于BP神经网络的污水数据清洗方法的清洗效果对比和清洗误差对比,图 7为PSO算法优化ISVM模型参数后的数据清洗结果. 从图 8、9可以看出,相比于BP神经网络方法,基于ISVM的污水数据清洗方法得到的补偿数据和实际值相差较小,预测曲线能够较好地拟合目标曲线值. 结果表明,基于ISVM的城市污水数据清洗方法能够通过非线性映射在高维空间进行回归,得到待补偿污水数据(如DO的质量浓度)与采集特征变量之间的关系,比基于BP神经网络的数据清洗方法具有更好的缺失数据补偿精度,可以获得更加精准的数据清洗效果. 同时运用PSO算法优化ISVM模型参数,从图 10可以看出,经过参数调优后的模型具有更精确的数据清洗能力,误差稳定在可接受范围内.


